
Content-based Movie Recommendation System
Updated:
1. Netflix Movies: Recommendation Engine
1.1 Setting the Context
In this blog, we will build a straightforward content-based recommendation system on Netflix data. But before getting to that point, we need to preprocess the data and understand the variables. The workflow is as follows:
- A 3-step missing value imputation process
- Building a Content-based Recommender System Maximum runtime of the notebook - 5-6 mins
1.2 Setup
# Data handling
import numpy as np
import pandas as pd
from collections import Counter
import time, math
# Parallel Tasking
from joblib import Parallel, delayed
# Web Crawling
from bs4 import BeautifulSoup
import requests
import matplotlib.pyplot as plt
# For the recommender system
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.preprocessing import MultiLabelBinarizer
1.3 Dataset : Kaggle
The tabular dataset that we will use in this notebook consists of listings of all the movies and tv shows available on Netflix, along with details such as - cast, directors, ratings, release year, duration, etc. The data is downloaded from Kaggle.
netflix_data = pd.read_csv("Data/netflix_titles.csv")
netflix_data.head(2)
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s1 | Movie | Dick Johnson Is Dead | Kirsten Johnson | NaN | United States | September 25, 2021 | 2020 | PG-13 | 90 min | Documentaries | As her father nears the end of his life, filmm... |
| 1 | s2 | TV Show | Blood & Water | NaN | Ama Qamata, Khosi Ngema, Gail Mabalane, Thaban... | South Africa | September 24, 2021 | 2021 | TV-MA | 2 Seasons | International TV Shows, TV Dramas, TV Mysteries | After crossing paths at a party, a Cape Town t... |
Having a glance at the first two rows of the dataset tells us there are some missing values in the data. But we will deal with it later. First, we will understand what these variables represent.
| Variable | Description |
|---|---|
| show_id | Unique ID for every Movie / Tv Show |
| type | Identifier - A Movie or TV Show |
| title | Title of the Movie / Tv Show |
| director | Director of the Movie |
| cast | Actors involved in the movie / show |
| country | Country where the movie / show was produced |
| date_added | Date it was added on Netflix |
| release_year | Actual Release year of the move / show |
| rating | TV Rating of the movie / show |
| duration | Total Duration - in minutes or number of seasons |
| listed_in | Genere |
| description | The summary description |
1.4 Data Exploration
1.4.1 Filter only movies data and remove duplicate rows
netflix_data.describe(include='all').head(4)
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 8807 | 8807 | 8807 | 6173 | 7982 | 7976 | 8797 | 8807.0 | 8803 | 8804 | 8807 | 8807 |
| unique | 8807 | 2 | 8807 | 4528 | 7692 | 748 | 1767 | NaN | 17 | 220 | 514 | 8775 |
| top | s1 | Movie | Dick Johnson Is Dead | Rajiv Chilaka | David Attenborough | United States | January 1, 2020 | NaN | TV-MA | 1 Season | Dramas, International Movies | Paranormal activity at a lush, abandoned prope... |
| freq | 1 | 6131 | 1 | 19 | 19 | 2818 | 109 | NaN | 3207 | 1793 | 362 | 4 |
There are 8807 rows in the dataset. We will focus only on movies data (not TV shows) and build a recommendation system on it.
netflix_data.groupby('type').count()
| show_id | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| type | |||||||||||
| Movie | 6131 | 6131 | 5943 | 5656 | 5691 | 6131 | 6131 | 6129 | 6128 | 6131 | 6131 |
| TV Show | 2676 | 2676 | 230 | 2326 | 2285 | 2666 | 2676 | 2674 | 2676 | 2676 | 2676 |
We can observe 6131 movies and 2676 tv shows on Netflix. So, we will only filter the movies data from the original dataset.
movies_data = netflix_data.loc[netflix_data["type"]=="Movie",].copy()
movies_data["title"] = movies_data['title'].str.strip().str.lower()
temp = movies_data['title'].value_counts()
movies_data.loc[movies_data["title"].isin(list(temp.index[temp>1])),]
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 159 | s160 | Movie | love in a puff | Pang Ho-cheung | Miriam Chin Wah Yeung, Shawn Yue, Singh Hartih... | Hong Kong | September 1, 2021 | 2010 | TV-MA | 103 min | Comedies, Dramas, International Movies | When the Hong Kong government enacts a ban on ... |
| 303 | s304 | Movie | esperando la carroza | Alejandro Doria | Luis Brandoni, China Zorrilla, Antonio Gasalla... | Argentina | August 5, 2021 | 1985 | TV-MA | 95 min | Comedies, Cult Movies, International Movies | Cora has three sons and a daughter and she´s a... |
| 3371 | s3372 | Movie | consequences | Ozan Açıktan | Nehir Erdoğan, Tardu Flordun, İlker Kaleli, Se... | Turkey | October 25, 2019 | 2014 | TV-MA | 106 min | Dramas, International Movies, Thrillers | Secrets bubble to the surface after a sensual ... |
| 6529 | s6530 | Movie | consequences | Ozan Açıktan | Nehir Erdoğan, Tardu Flordun, İlker Kaleli, Se... | Turkey | October 25, 2019 | 2014 | TV-MA | 106 min | Dramas, International Movies, Thrillers | Secrets bubble to the surface after a sensual ... |
| 6705 | s6706 | Movie | esperando la carroza | Alejandro Doria | Luis Brandoni, China Zorrilla, Antonio Gasalla... | Argentina | July 15, 2018 | 1985 | NR | 95 min | Comedies, Cult Movies, International Movies | Cora has three sons and a daughter and she´s a... |
| 7345 | s7346 | Movie | love in a puff | Pang Ho-cheung | Miriam Chin Wah Yeung, Shawn Yue, Singh Hartih... | Hong Kong | August 1, 2018 | 2010 | TV-MA | 103 min | Comedies, Dramas, International Movies | When the Hong Kong government enacts a ban on ... |
It looks like these are surely duplicate rows. So, we can remove either of the rows for each movie.
movies_data = movies_data.drop([6529,6705,7345])
1.4.2 Missing Value Handling/ Imputation
Instead of directly removing rows with missing values, we try to impute as much data as possible with high accuracy. This process involves three steps:
- Stage 1: Remove rows for columns with very, very few missing values
- Stage 2: Web crawling based imputation to achieve high accuracy
- Stage 3: Replace the remaining NaN values with an empty string to preserve information in other columns
1.4.2.1 Handling Missing Values - Stage 1 (Drop Rows)
print("Rows with missing values in the data: "+
str(round(100*sum(movies_data.isnull().any(axis=1))/movies_data.shape[0],2))+"%")
movies_data.isna().sum()
Rows with missing values in the data: 15.44%
show_id 0
type 0
title 0
director 188
cast 475
country 440
date_added 0
release_year 0
rating 2
duration 3
listed_in 0
description 0
dtype: int64
We can see several missing values in the director, cast, country columns and a very few missing values in the rating and duration columns. Let’s remove the rows with missing values in the rating and duration columns.
movies_data.dropna(subset=["rating","duration"], how='any', inplace=True)
print("Rows with missing values in the data: "+str(round(100*sum(movies_data.isnull().any(axis=1))/movies_data.shape[0],2))+"%")
movies_data.isna().sum()
Rows with missing values in the data: 15.37%
show_id 0
type 0
title 0
director 187
cast 475
country 439
date_added 0
release_year 0
rating 0
duration 0
listed_in 0
description 0
dtype: int64
nan_rows_df = movies_data[movies_data.isnull().any(axis=1)]
nan_rows_df.head(2)
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s1 | Movie | dick johnson is dead | Kirsten Johnson | NaN | United States | September 25, 2021 | 2020 | PG-13 | 90 min | Documentaries | As her father nears the end of his life, filmm... |
| 6 | s7 | Movie | my little pony: a new generation | Robert Cullen, José Luis Ucha | Vanessa Hudgens, Kimiko Glenn, James Marsden, ... | NaN | September 24, 2021 | 2021 | PG | 91 min | Children & Family Movies | Equestria's divided. But a bright-eyed hero be... |
There are still more than 15% rows with missing values. So instead of removing those rows, we will try to impute the data with high accuracy.
1.4.2.2 Handling Missing Values - Stage 2 (Web Crawling)
The concept behind this is simple. For example, let’s look at the first row in the above table where the movie title is “Dick Johnson Is Dead” and the cast has NaN value. First of all, why is this value missing? There could be two potential reasons.
- Netflix might not log this information on their platform. Hence the value was missing
- This data file is being maintained on Kaggle and constantly updated by only a single person. So, there might be some manual errors involved while copying the data into a CSV file.
However, we can’t attribute each row with missing value to a specific reason. In either case, we will look up the movie on IMDb and get the director, cast, and country of origin data.
You can also look at this sample URL and see how we can extract the director, cast, and country of origin variables from it.
# Functions to extract the director, cast, country of origin data from a page source
def get_director(soup):
"""
Extract the director information from the HTML source data
Args:
soup: object (page source) obtained from scraping the website using BeautifulSoup() function
Returns:
director: returns a string containing directors of a movie separated by a comma
"""
try:
director = ""
temp = soup.find("section",{"data-testid":"title-cast"}).find_all("li",{"class","ipc-metadata-list__item"})
if len(temp)==4: #if the section on the page in found
director_soups = temp[0].find_all("a")
for director_soup in director_soups:
name = director_soup.get_text().strip()
director = director + name + ", "
director = director[:-2]
return director
else:
return director
except:
return director
def get_cast(soup):
"""
Extract the cast information from the HTML source data
Args:
soup: object (page source) obtained from scraping the website using BeautifulSoup() function
Returns:
cast: returns a string containing all the cast members of a movie separated by a comma
"""
try:
cast = ""
cast_soups = soup.find("section",{"data-testid":"title-cast"}).find_all("a",{"data-testid":"title-cast-item__actor"})
for cast_soup in cast_soups:
name = cast_soup.get_text().strip()
cast = cast + name + ", "
cast = cast[:-2]
return cast
except:
return cast
def get_country(soup):
"""
Extract the country information from the HTML source data
Args:
soup: object (page source) obtained from scraping the website using BeautifulSoup() function
Returns:
country: returns a string containing all the countries of origin of a movie separated by a comma
"""
try:
country = ""
countries_soups = soup.find("div",{"data-testid":"title-details-section"}).find("li",{"data-testid":"title-details-origin"}).find_all("a")
for countries_soup in countries_soups:
name = countries_soup.get_text().strip()
country = country + name + ", "
country = country[:-2]
return country
except:
return country
%%time
def imdb_requests(row):
"""
Main Function that extracts the director, cast, and countries of origin information for each row with NaN value
Args:
row: dataframe row containing atleast one NaN value
Returns:
main_dict: returns a dictionary containing title, show_id, director, cast, country as keys and their
corresponding values as dictionary values
"""
main_dict = {}
main_dict["title"] = row["title"]
main_dict["show_id"] = row["show_id"]
try:
source = requests.get("https://www.imdb.com/find?ref_=nv_sr_fn&q="+str(main_dict["title"]))
source.raise_for_status()
soup = BeautifulSoup(source.text,'html.parser')
#take the first URL on the results page and extract information from it
title = soup.find("td",{"class":"result_text"}).find('a').get("href")
new_url = "https://www.imdb.com"+title
source = requests.get(new_url)
source.raise_for_status()
soup = BeautifulSoup(source.text,'html.parser')
main_dict["director"] = get_director(soup)
main_dict["cast"] = get_cast(soup)
main_dict["country"] = get_country(soup)
except:
pass
return main_dict
"""
The below four rows calls several URL requests using a parallel function, convert an array of dictionaries
to a data frame, and replace empty string with NaN values (to impute them later).
This code takes close to 5 minutes to run. I ran this already and generated the intermediate file,
which I will use in the subsequent sections.
"""
# nan_rows_search_results = Parallel(n_jobs=-1)(delayed(imdb_requests)(row) for index, row in nan_rows_df.iterrows())
# nan_rows_search_results_df = pd.DataFrame(nan_rows_search_results)
# nan_rows_search_results_df = nan_rows_search_results_df.replace('',np.nan,regex=True)
# nan_rows_search_results_df.to_csv("IMDB_intermediate_data.csv",index=False)
nan_rows_search_results_df = pd.read_csv("IMDB_intermediate_data.csv")
CPU times: user 4.45 ms, sys: 1.67 ms, total: 6.12 ms
Wall time: 5.25 ms
Single Core vs Multi Core Computations:
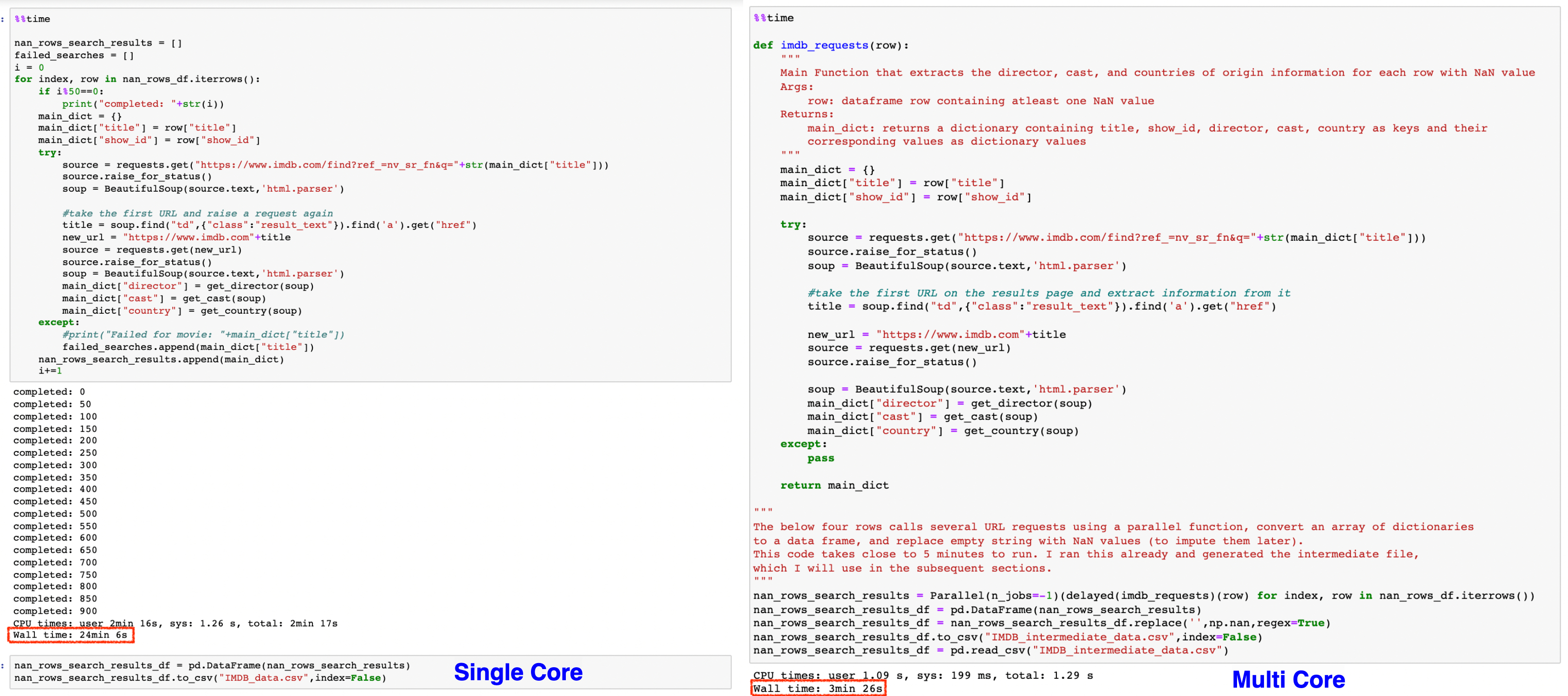
We observe that using a parallel function helps us reduce the run time to 15%.
movies_data.cast = np.where(movies_data.cast.isnull(),movies_data.show_id.map(nan_rows_search_results_df.set_index('show_id').cast),movies_data.cast)
movies_data.country = np.where(movies_data.country.isnull(),movies_data.show_id.map(nan_rows_search_results_df.set_index('show_id').country),movies_data.country)
movies_data.director = np.where(movies_data.director.isnull(),movies_data.show_id.map(nan_rows_search_results_df.set_index('show_id').director),movies_data.director)
print("Rows with missing values in the data: "+str(round(100*sum(movies_data.isnull().any(axis=1))/movies_data.shape[0],2))+"%")
movies_data.isna().sum()
Rows with missing values in the data: 5.42%
show_id 0
type 0
title 0
director 109
cast 104
country 183
date_added 0
release_year 0
rating 0
duration 0
listed_in 0
description 0
dtype: int64
We now only have about 5.4% of the missing rows in the data. Unfortunately, we could not find the rest of them from the IMDB data. So, we replace them with an empty string.
1.4.2.3 Handling Missing Values - Stage 3 (Replace with Empty String)
movies_data = movies_data.replace(np.nan,'',regex=True)
movies_data.reset_index(drop=True,inplace=True)
print("Rows with missing values in the data: "+str(round(100*sum(movies_data.isnull().any(axis=1))/movies_data.shape[0],2))+"%")
movies_data.isna().sum()
Rows with missing values in the data: 0.0%
show_id 0
type 0
title 0
director 0
cast 0
country 0
date_added 0
release_year 0
rating 0
duration 0
listed_in 0
description 0
dtype: int64
1.4.3 Parsing the date_added, duration columns
We will extract the year, month, and day of the week data from the date_added column and analyze them separately to generate more insights later. Also, we parse the duration column into a numeric column.
# Year added column
movies_data['year_added'] = movies_data['date_added'].apply(lambda x: x.split(" ")[-1])
movies_data['year_added'] = movies_data["year_added"].astype("int")
# Month added column
movies_data['month_added'] = movies_data['date_added'].apply(lambda x: x.split(" ")[0])
movies_data['date_added'] = pd.to_datetime(movies_data['date_added'])
movies_data['day_of_week'] = movies_data['date_added'].dt.day_name()
movies_data[['month_added','year_added','day_of_week']].head()
| month_added | year_added | day_of_week | |
|---|---|---|---|
| 0 | September | 2021 | Saturday |
| 1 | September | 2021 | Friday |
| 2 | September | 2021 | Friday |
| 3 | September | 2021 | Friday |
| 4 | September | 2021 | Thursday |
movies_data['duration']=movies_data['duration'].str.replace(' min','')
movies_data['duration']=movies_data['duration'].astype(str).astype(int)
1.5 Content-based recommendation engine on multiple metrics
Now that we have a fair understanding of the variables, we will build the recommendation engine using a few of them. There are two main types of recommendation engines: content-based filtering and collaborative filtering. We will try to build the former one in this notebook.
Content-based filtering works on the principle that you will also like another item if you like a particular item. For example, to provide movie recommendations, algorithms use several movie attributes like title, genre, director, cast to compare movies using cosine or euclidean distances. One of the major downsides of this approach is that this system limits recommending movies similar to what the person has already watched. However, we will not address this in this notebook.
features = ['title','director','cast','listed_in']
def clean_data(df,features):
df_subset = df[features].copy()
df_subset['main_column'] = ""
for feature in features:
if feature!="description":
df_subset[feature] = df_subset[feature].apply(lambda x: str.lower(x.replace(" ", "")))
df_subset["main_column"] = df_subset["main_column"] + ' ' + df_subset[feature]
return df_subset
We need to remove the spaces from the data before combining the features to a new column. This is required because, for example, there are 84 directors with Michael as part of their name, but none of them have a common full name. So it doesn’t make sense to recommend a director’s movies only because they have a part of their name common to another director. The same logic applies to the other columns.
movies_data_subset = clean_data(movies_data,features)
movies_data_subset.head(2)
| title | director | cast | listed_in | main_column | |
|---|---|---|---|---|---|
| 0 | dickjohnsonisdead | kirstenjohnson | michaelhilow,anahoffman,dickjohnson,kirstenjoh... | documentaries | dickjohnsonisdead kirstenjohnson michaelhilow... |
| 1 | mylittlepony:anewgeneration | robertcullen,joséluisucha | vanessahudgens,kimikoglenn,jamesmarsden,sofiac... | children&familymovies | mylittlepony:anewgeneration robertcullen,josé... |
We use the TF-IDF (term frequency–inverse document frequency) matrix to process the new combined column main_column that was created in the previous step. You can also read about TF-IDF here. We then use cosine-similarity to create a score between each pair of movies.
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(movies_data_subset['main_column'])
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
1.5.1 Which movies are the most similar to each other?
movie_titles_df = pd.DataFrame(movies_data['title']).reset_index()
movie_titles_df.columns = ["row_id","Title"]
cosine_sim_df = pd.DataFrame(cosine_sim).reset_index()
cosine_sim_df_melted = pd.melt(cosine_sim_df, id_vars=['index'], value_vars=list(cosine_sim_df.columns[1:]))
cosine_sim_df_melted.columns = ["row_id1","row_id2","similarity"]
cosine_sim_df_melted = cosine_sim_df_melted.sort_values("similarity",ascending=False)
cosine_sim_df_melted = cosine_sim_df_melted.loc[cosine_sim_df_melted["row_id1"]<cosine_sim_df_melted["row_id2"],].reset_index(drop=True)
Filter movies with very high similarity
thres = 0.9
filtered_df = cosine_sim_df_melted.loc[cosine_sim_df_melted["similarity"]>thres,].copy()
filtered_df = filtered_df.merge(movie_titles_df,left_on="row_id1",right_on="row_id")
filtered_df = filtered_df.merge(movie_titles_df,left_on="row_id2",right_on="row_id")
filtered_df = filtered_df[["Title_x","Title_y","similarity"]].copy()
filtered_df.columns = ["Movie1","Movie2","Similarity"]
filtered_df["Similarity"] = round(filtered_df["Similarity"],2)
filtered_df
| Movie1 | Movie2 | Similarity | |
|---|---|---|---|
| 0 | oh! baby (tamil) | oh! baby | 0.96 |
| 1 | oh! baby (malayalam) | oh! baby | 0.96 |
| 2 | oh! baby (malayalam) | oh! baby (tamil) | 0.93 |
| 3 | solo: a star wars story | solo: a star wars story (spanish version) | 0.96 |
| 4 | rogue warfare: death of a nation | rogue warfare | 0.96 |
| 5 | rogue warfare: the hunt | rogue warfare | 0.96 |
| 6 | rogue warfare: death of a nation | rogue warfare: the hunt | 0.92 |
| 7 | boomika | boomika (hindi) | 0.95 |
| 8 | boomika | boomika (telugu) | 0.95 |
| 9 | boomika | boomika (malayalam) | 0.94 |
| 10 | petta (telugu version) | petta | 0.94 |
| 11 | bo burnham: what. | bo burnham: make happy | 0.93 |
| 12 | godzilla the planet eater | godzilla city on the edge of battle | 0.93 |
| 13 | osuofia in london | osuofia in london ii | 0.92 |
| 14 | tughlaq durbar | tughlaq durbar (telugu) | 0.92 |
| 15 | naruto shippuden the movie: blood prison | naruto shippuden : blood prison | 0.92 |
| 16 | sarvam thaala mayam (telugu version) | sarvam thaala mayam (tamil version) | 0.92 |
| 17 | chris d'elia: man on fire | chris d'elia: incorrigible | 0.92 |
| 18 | octonauts & the ring of fire | octonauts & the great barrier reef | 0.91 |
| 19 | the twilight saga: breaking dawn: part 1 | the twilight saga: breaking dawn: part 2 | 0.91 |
| 20 | baahubali 2: the conclusion (hindi version) | baahubali 2: the conclusion (tamil version) | 0.91 |
| 21 | baahubali 2: the conclusion (malayalam version) | baahubali 2: the conclusion (tamil version) | 0.90 |
| 22 | baahubali 2: the conclusion (hindi version) | baahubali 2: the conclusion (malayalam version) | 0.90 |
| 23 | baahubali: the beginning (hindi version) | baahubali: the beginning (tamil version) | 0.91 |
| 24 | baahubali: the beginning (malayalam version) | baahubali: the beginning (tamil version) | 0.90 |
| 25 | baahubali: the beginning (hindi version) | baahubali: the beginning (malayalam version) | 0.90 |
| 26 | the magic school bus rides again the frizz con... | the magic school bus rides again kids in space | 0.91 |
| 27 | game over (hindi version) | game over (tamil version) | 0.90 |
| 28 | game over (hindi version) | game over (telugu version) | 0.90 |
| 29 | game over (tamil version) | game over (telugu version) | 0.90 |
We observe that the same movie with different versions in multiple languages has the highest score based on the results. If we do not want them as part of our recommendations, we can remove the duplicate entries in the preprocessing step. For now, we will keep them as part of our model.
movies_data_subset=movies_data_subset.reset_index()
indices = pd.Series(movies_data_subset.index, index=movies_data_subset['title'])
1.5.2 Let’s get some recommendations for a movie
def get_recommendations_new(title, cosine_sim, n):
"""
Find the similar movies to a given movie
Args:
title: movie title to which we find recommendations
cosine_sim: cosine similarity matrix for finding similar movies
n: number of movies to recommend
Returns:
results_df: returns a dataframe containing the list of recommended movies with rowids
and their similarity score
"""
title = title.replace(' ','').lower()
idx = indices[title]
#pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
#sort the movies based on cosine similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the top n most similar movies
sim_scores = sim_scores[1:(n+1)]
# Get their movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
results_df = pd.DataFrame(movies_data['title'].iloc[movie_indices])
results_df["score"] = np.round(np.array(sim_scores)[:,1],2)
results_df = results_df.reset_index(drop=False)
results_df.columns = ["RowID","Recommended Movie","Similarity Score"]
return results_df
movie_title = "pk"
recommendations_df = get_recommendations_new(movie_title,cosine_sim,5)
temp_df = movies_data.loc[movies_data.title.isin([movie_title]+list(recommendations_df["Recommended Movie"]))]
temp_df = temp_df[features].reset_index(drop=True)
temp_df = temp_df.merge(recommendations_df,left_on="title",right_on = "Recommended Movie",how="outer")
temp_df = temp_df.sort_values("Similarity Score",ascending=False)
temp_df = temp_df[["title","director","cast","listed_in","Similarity Score"]]
temp_df["new"] = range(1,len(temp_df)+1)
temp_df.loc[temp_df.title==movie_title,'new'] = 0
temp_df = temp_df.sort_values("new").drop('new', axis=1)
temp_df
| title | director | cast | listed_in | Similarity Score | |
|---|---|---|---|---|---|
| 5 | pk | Rajkumar Hirani | Aamir Khan, Anuskha Sharma, Sanjay Dutt, Saura... | Comedies, Dramas, International Movies | NaN |
| 2 | 3 idiots | Rajkumar Hirani | Aamir Khan, Kareena Kapoor, Madhavan, Sharman ... | Comedies, Dramas, International Movies | 0.27 |
| 4 | sanju | Rajkumar Hirani | Ranbir Kapoor, Vicky Kaushal, Paresh Rawal, So... | Dramas, International Movies | 0.18 |
| 3 | drive | Tarun Mansukhani | Jacqueline Fernandez, Sushant Singh Rajput, Bo... | Action & Adventure, International Movies | 0.17 |
| 1 | taare zameen par | Aamir Khan | Aamir Khan, Darsheel Safary, Tanay Chheda, Tis... | Dramas, International Movies | 0.15 |
| 0 | madness in the desert | Satyajit Bhatkal | Aamir Khan, Ashutosh Gowariker | Documentaries, International Movies | 0.12 |
1.6 Summary and Scope for Improvement
1.6.1 Summary
We started with data preprocessing steps that involved removing duplicate entries, missing value imputation stages, and feature extractions. Using web crawling, we used a unique approach to imputing missing data with high accuracy. Finally, we converted the preprocessed text into a TF-IDF matrix and calculated the scores using the cosine similarity function to create the final recommendation system.
1.6.2 Scope for Improvement
The below pointers mention a few ways to improve the workflow of this notebook:
- We did not analyze the
descriptioncolumn, which contains a movie summary, but it can also be added to the existing system to generate more accurate recommendations. - Word clouds can also be plotted when analyzing the
descriptioncolumn.